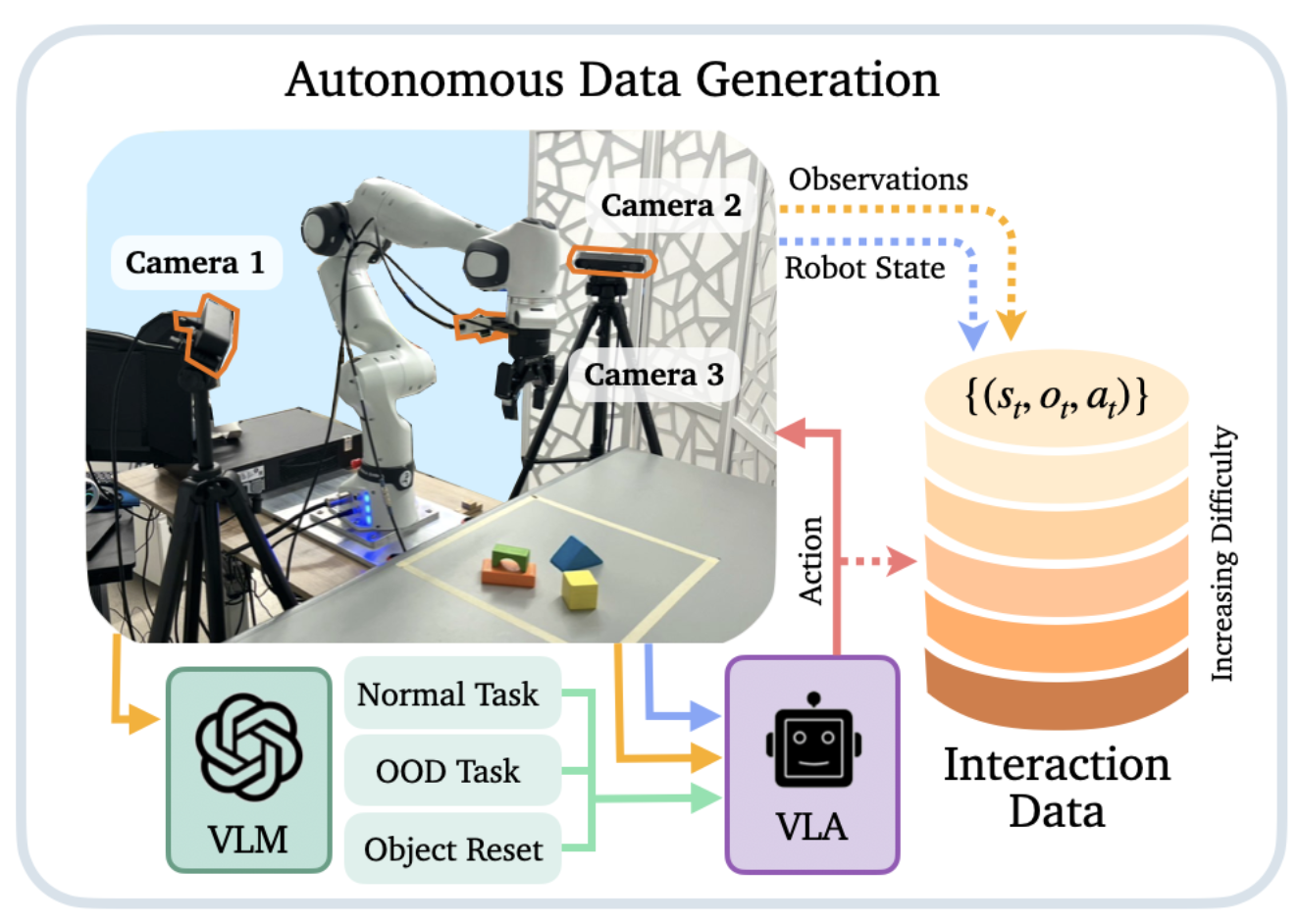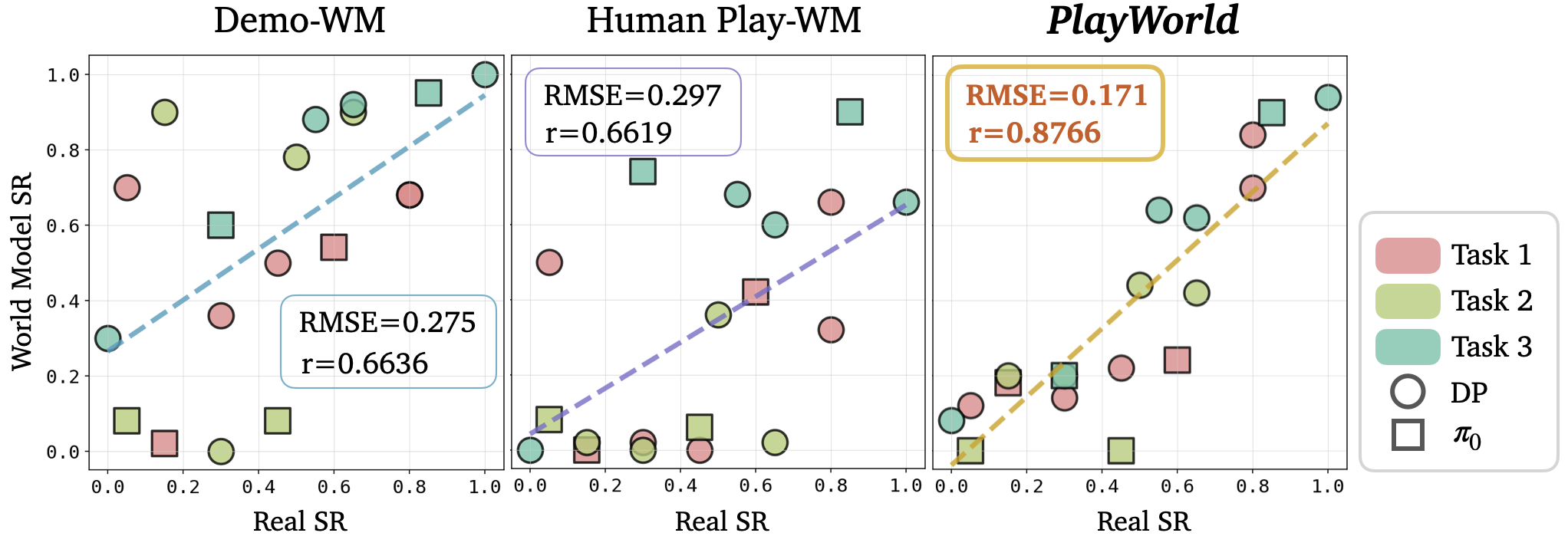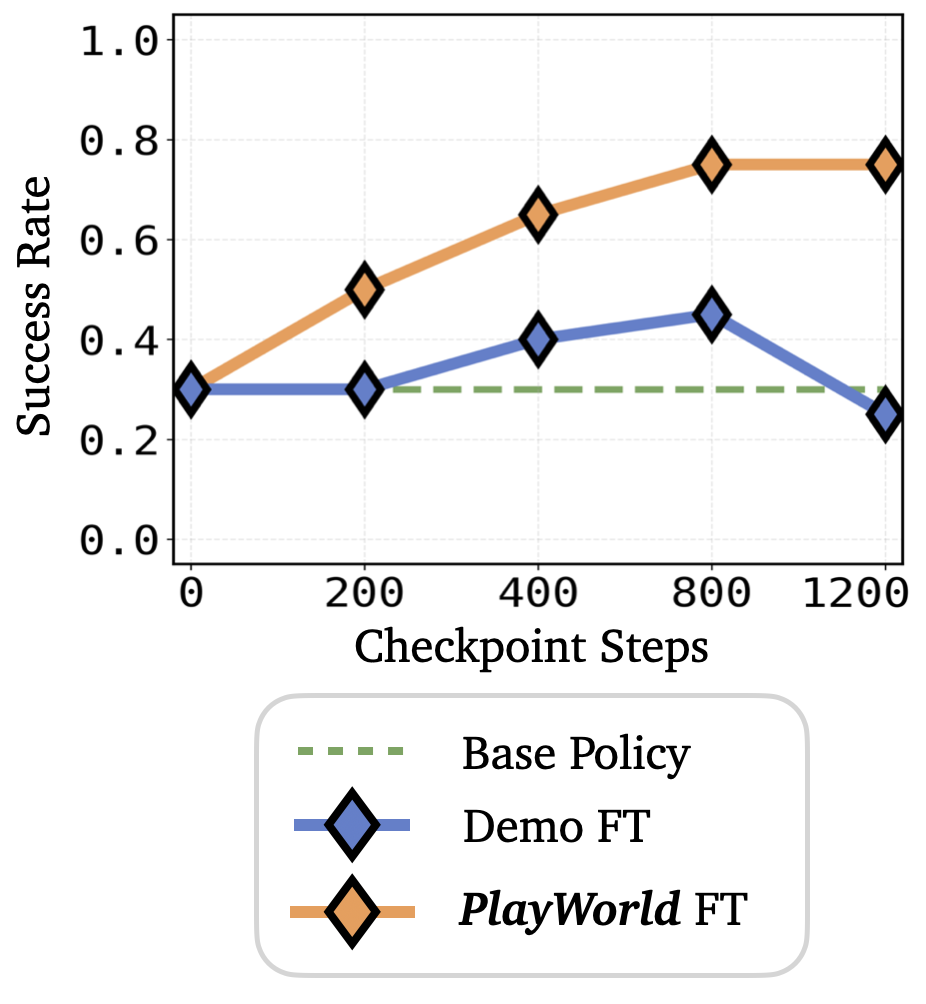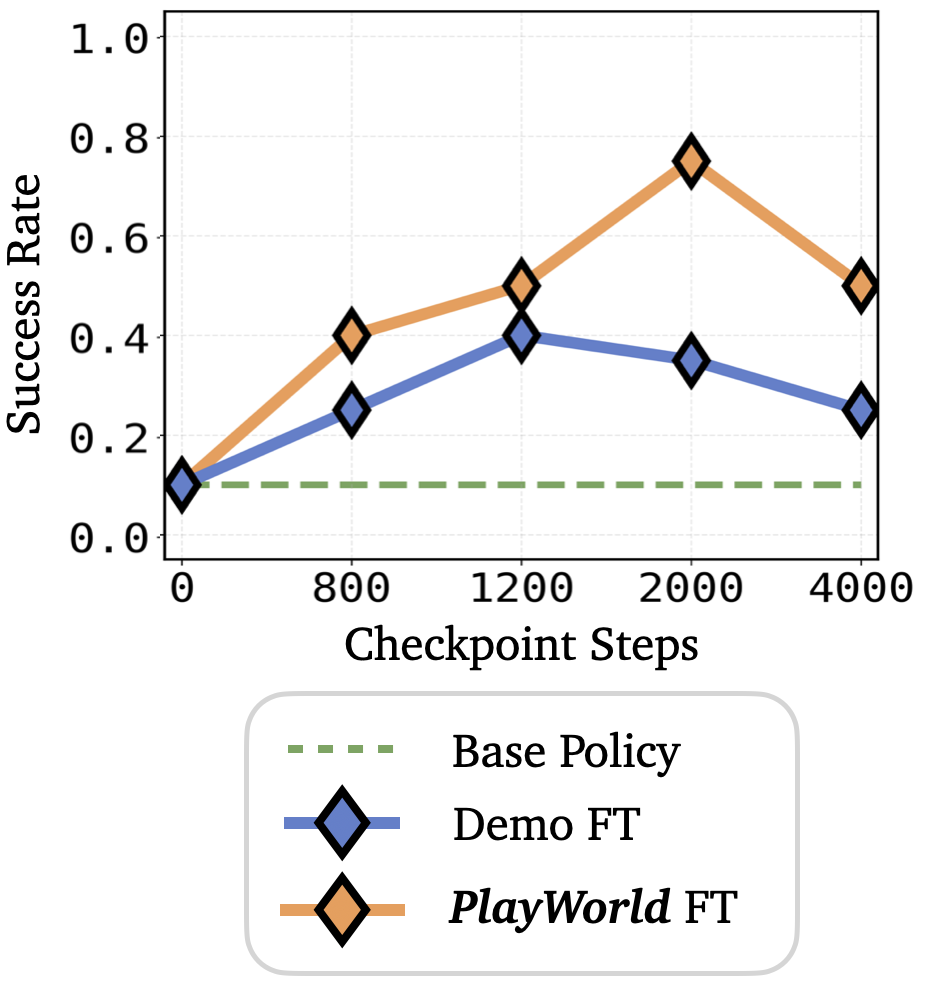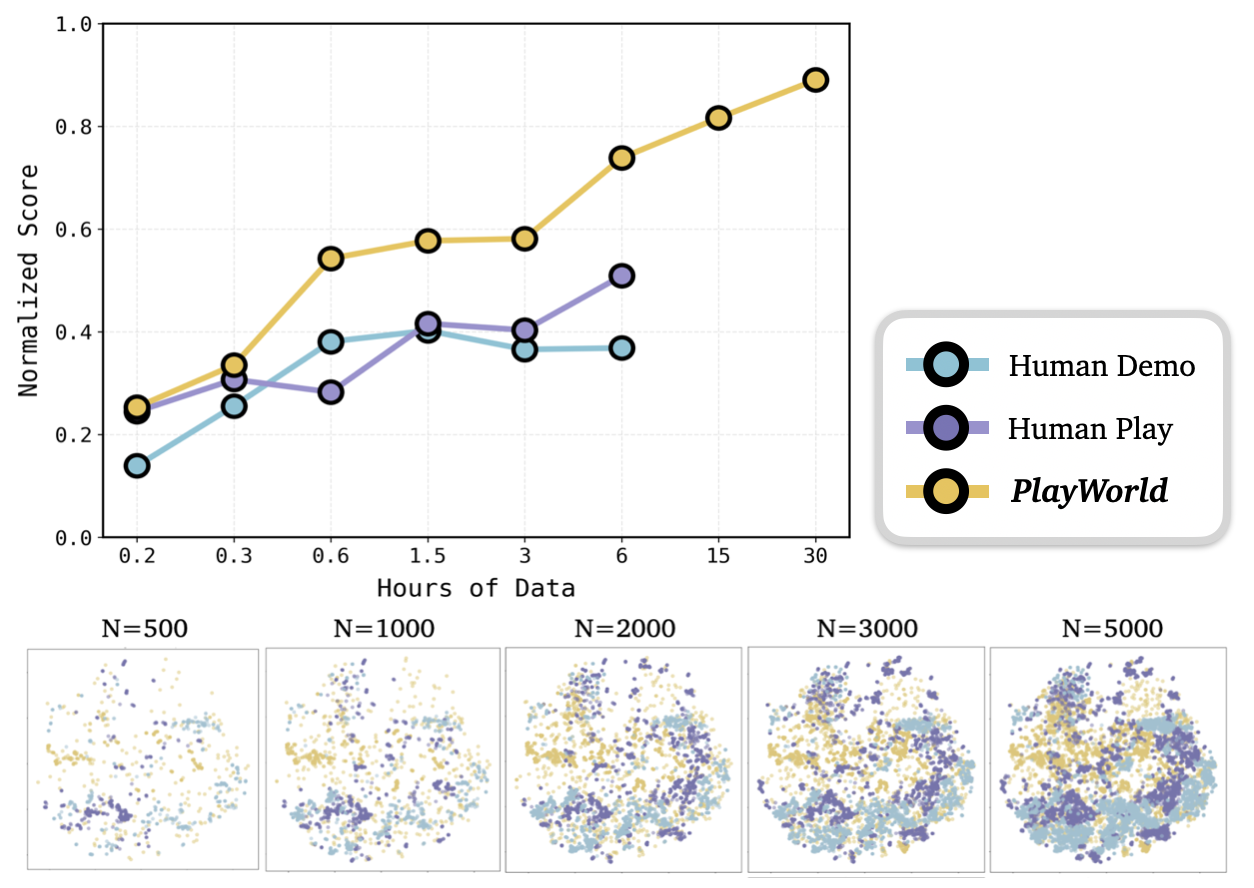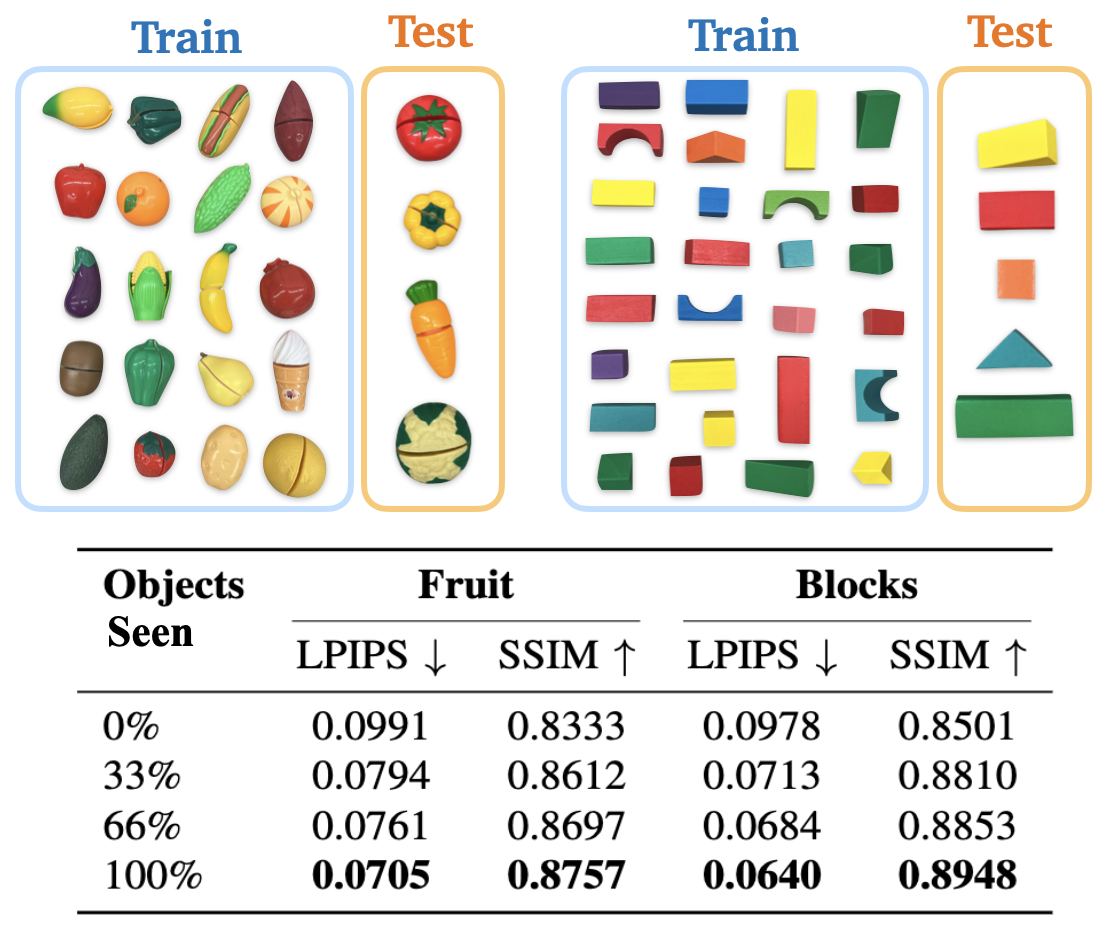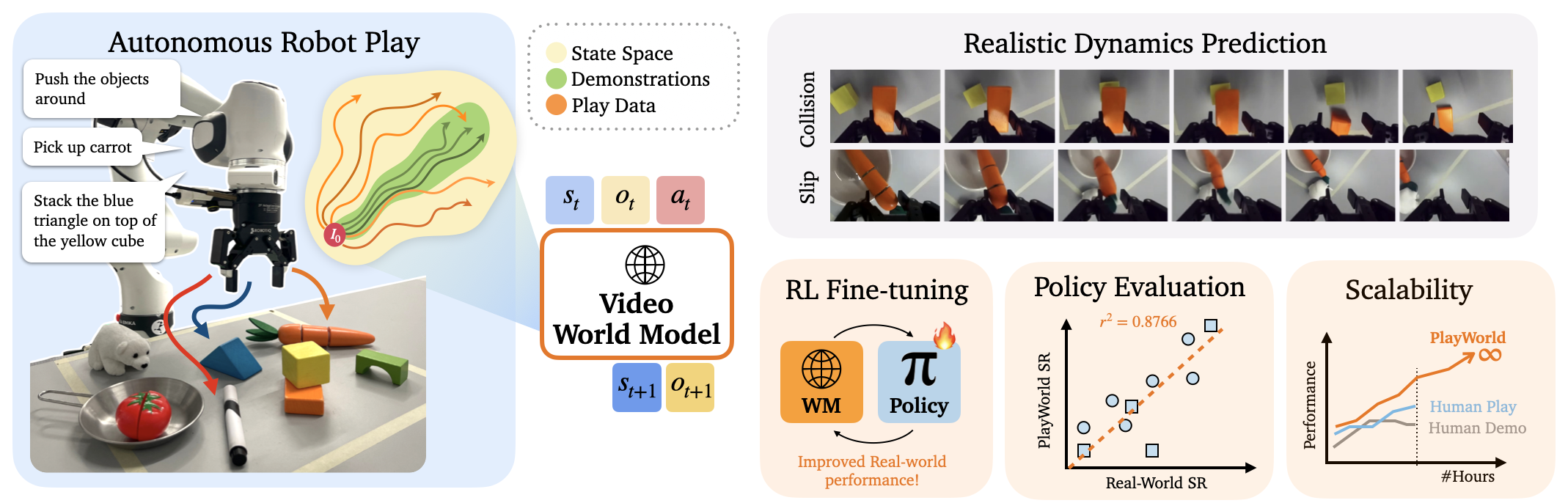
We introduce PlayWorld, a scalable framework for training high-fidelity Action-Conditioned Robot World Models using Autonomous Play. Instead of relying on success-biased human demonstrations, it continuously gathers diverse, contact-rich interactions and failure cases that better match downstream policy behaviors. The resulting model enables accurate dynamics prediction, reliable policy evaluation, and effective world-model-based RL fine-tuning that improves real-world performance.